At the PNU x Upstage DOCUMENT AI CHALLENGE, we built DocDoc, a chatbot service for medical staff working overseas. The goal was to answer user questions by referring to relevant medical papers.
At first, we simply passed the user's question to the LLM and generated an answer. But in a medical and paper-based context, a natural-sounding answer could still be risky. Even if the sentence looked fluent, it could mix in content that was not in the documents, or state something with an unclear source as if it were certain.
Another problem was that simple vector search was not always enough. Even if a document chunk was semantically similar to the question, it was sometimes weak as actual evidence for the user's question. At first, I thought plausible Pinecone search results would be enough. But after checking the generated answers, I found cases where "related but weak as evidence" documents were included in the context.
So I limited the scope of the feature. It was not a tool that directly provided medical advice. It was closer to an assistant that helped users find related documents and check the evidence.
This post is a record of applying a RAG pipeline while thinking about how to attach evidence to LLM answers.
Problem
The initial implementation was simple. When the user asked a question, the question was sent to the LLM, and the model generated an answer. As a feature, it returned results quickly. But when I thought about real usage, there were problems.
- Unsupported sentences could be mixed into the answer.
- The model could talk about content that did not exist in the documents.
- The source of the answer was unclear.
- In a medical and paper-based context, a natural sentence itself could become a risk.
- Vector search results did not always match the exact intent of the question.
This did not feel like a problem that could be solved simply by switching to a bigger model. I needed a structure where the model first received relevant documents and then answered within that range.
Approach
The goal was to reduce situations where the model made unsupported claims. So before answer generation, I changed the flow to find related document chunks first and pass them into the model as context.
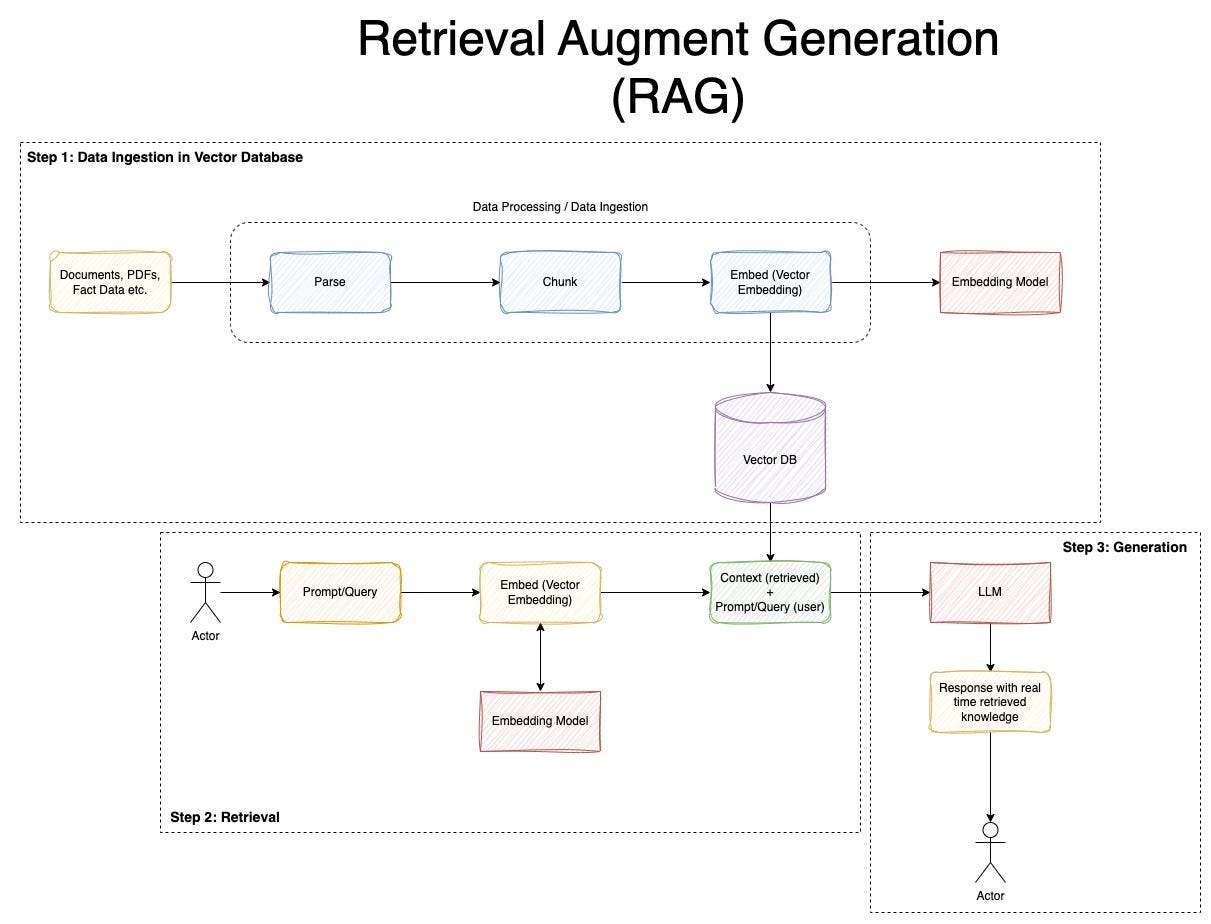
The flow was designed like this.
- Parse medical papers and split them into searchable document chunks.
- Convert the user question into an embedding vector.
- Search similar document chunk candidates from Pinecone.
- Rerank the retrieved candidates based on relevance to the question.
- Include the final selected document chunks in the LLM prompt as context.
- Generate an answer within the context and show the evidence together.
Even after applying this structure, I could not say that the answers became completely safe. But the result became closer to a form where the user could check the evidence along with the answer.
Reranking
At first, I used Pinecone-based vector search to retrieve related documents. This worked well for quickly finding broadly relevant documents. However, the top search results were not always the strongest evidence for the question.
For example, a document chunk related to the same disease, drug, or symptom could be retrieved, but it might still be slightly away from the specific evidence needed by the question. If that kind of document is passed into the LLM context, the answer can look plausible while being weakly supported.
So I added a reranking step after the initial vector search. Pinecone narrowed down the candidate set quickly, and reranking evaluated the candidate documents again based on question relevance to choose what should go into the final context.
After separating the flow this way, the search process became easier to understand. Vector search was close to candidate retrieval, and reranking was close to a correction step for improving evidence quality. It did not remove hallucination completely, but it helped reduce problems caused by passing weak context into the LLM.
Implementation
When applying RAG, I did not only focus on controlling the model's wording. I also tried to narrow the search range before the answer and improve the quality of the retrieved context.
If document chunks are too broad, unrelated content can be included. If they are too narrow, needed context can be lost. So I had to keep checking how to split the documents and in what order to place the search results into the prompt.
The stack used at the time was:
- Vector DB: Pinecone
- Embedding: Upstage Embeddings
- Reranking: candidate document reordering based on question relevance
- LLM: Upstage Solar Pro 2
- Framework: LangChain
- Backend: Node.js, Express
Along with applying the technology, I also had to define the answer scope. I designed the flow so that the model explained based on documents and avoided making claims outside the provided context.
SSE Streaming
After applying RAG, the service had to search documents, run reranking, insert the search results into the prompt, and then generate the answer. So response time could become longer than a simple LLM call.
From the user's point of view, if they only see loading for a long time, the service can feel stuck. So instead of sending the whole answer at once, I used Server-Sent Events, or SSE, to send generated text little by little.
There were two things I wanted from this approach.
- Show the generation process on the screen to reduce the feeling of waiting.
- Let the user know that the answer is still being generated before the full response is complete.
For LLM features, perceived responsiveness matters as much as answer quality. Especially in a structure like RAG, where search and generation are combined, how the response flow is shown to the user also needs to be considered.
Takeaway
This experience showed me that LLM-related problems often require designing the surrounding pipeline, not just replacing the model.
For document-based answers, I checked these points.
- Which documents support the answer?
- Do the search results match the user's intent well enough?
- Is the model avoiding claims outside the context?
- Can the user check the evidence for the answer?
- If generation takes time, does the user see progress?
RAG is not a tool that completely removes hallucination. It is a structure for putting evidence into the system. In DocDoc, document parsing, embedding, search, reranking, prompt construction, and SSE streaming all had to work together to make the answer more checkable.