PNU x Upstage DOCUMENT AI CHALLENGE에서 해외 파견 의료진을 돕는 챗봇 서비스 DocDoc을 만들었다. 목표는 사용자가 질문하면 관련 의학 문서를 참고해 답변을 만들어주는 것이었다.
처음에는 질문을 그대로 LLM에 전달해 답변을 생성하는 방식으로 시작했다. 하지만 의료·논문 맥락에서는 자연스러운 문장만으로는 부족했다. 답변이 읽기 좋게 보이더라도 실제 문서에 없는 내용을 섞거나, 출처가 모호한 내용을 단정하면 사용자가 잘못 받아들일 수 있기 때문이다.
또 하나 확인한 문제는 단순 벡터 검색만으로는 부족한 경우가 있다는 점이었다. 의미적으로 비슷한 문서 조각이 검색되더라도, 사용자의 실제 질문에 대한 근거로는 약한 경우가 있었다. 처음에는 Pinecone 검색 결과가 그럴듯하게 나오면 충분할 줄 알았는데, 실제 답변을 확인해보니 "관련은 있지만 답변 근거로는 애매한 문서"가 컨텍스트에 들어가는 경우가 있었다.
그래서 이 기능은 의료 조언을 직접 제공하는 도구가 아니라, 관련 문서를 찾고 근거를 확인하는 보조 도구로 범위를 정했다. 이 글은 LLM 답변에 근거를 어떻게 붙일지 고민하면서 RAG 파이프라인을 적용한 기록이다.
문제 상황
초기 구현은 단순했다. 사용자가 질문하면 LLM에 질문을 전달하고, 모델이 답변을 생성했다. 기능만 보면 빠르게 결과가 나왔지만, 실제 사용 상황을 생각하면 문제가 있었다.
- 근거 없는 문장이 섞일 수 있었다.
- 존재하지 않는 내용을 실제 문서 내용처럼 말할 수 있었다.
- 답변의 출처가 불명확했다.
- 의료·논문 맥락에서는 자연스러운 문장 자체가 리스크가 될 수 있었다.
- 벡터 검색 결과가 질문 의도와 정확히 맞지 않는 경우가 있었다.
이 문제는 단순히 더 큰 모델로 바꾼다고 바로 해결될 것 같지는 않았다. 모델이 참고할 문서를 먼저 정하고, 그 범위 안에서 답변하게 만드는 구조가 필요하다고 봤다.
해결 방법
목표는 모델이 근거 없이 단정하는 상황을 줄이는 것이었다. 그래서 답변 생성 전에 관련 문서 조각을 먼저 찾고, 그 결과를 컨텍스트로 넣는 RAG 구조로 바꿨다.
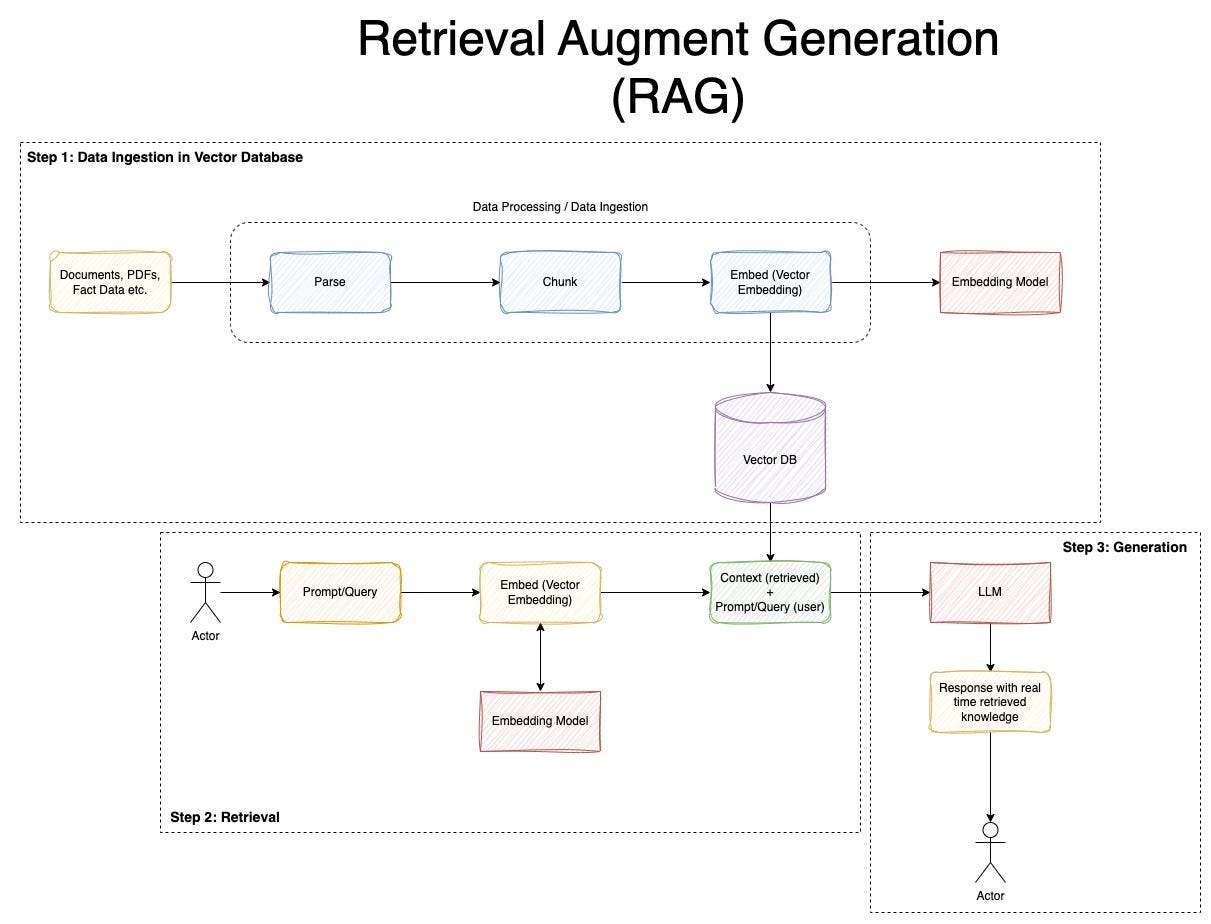
구현 흐름은 아래처럼 잡았다.
- 의료 논문을 파싱하고 검색 가능한 문서 조각으로 나눈다.
- 사용자 질문을 임베딩 벡터로 변환한다.
- Vector DB인 Pinecone에서 유사한 문서 조각 후보를 검색한다.
- 검색된 후보 문서를 질문 관련도 기준으로 reranking한다.
- 최종 선택된 문서 조각을 LLM 프롬프트에 컨텍스트로 포함한다.
- LLM은 컨텍스트 범위 안에서 답변을 생성하고, 근거를 함께 보여준다.
이 구조로 바꾼 뒤에도 답변이 완전히 안전해졌다고 말할 수는 없다. 다만 사용자가 답변의 근거를 함께 확인할 수 있는 형태에 가까워졌다.
Reranking 적용 이유
처음에는 Pinecone 기반 vector search만으로 관련 문서를 가져왔다. 이 방식은 넓은 의미의 관련 문서를 빠르게 찾는 데는 효과적이었다. 하지만 검색 결과의 상위 문서가 질문에 가장 직접적인 근거가 되지 않는 경우도 있었다.
예를 들어 같은 질병, 약물, 증상과 관련된 문서 조각이 검색되더라도, 실제 질문이 요구하는 판단 근거와는 조금 떨어져 있을 수 있었다. 이런 문서가 그대로 LLM 컨텍스트에 들어가면 답변이 그럴듯해 보여도 근거가 약해질 수 있다.
그래서 초기 벡터 검색 이후 reranking 단계를 추가했다. Pinecone은 후보군을 빠르게 좁히는 역할을 맡고, reranking은 후보 문서를 질문 관련도 기준으로 다시 평가해 최종 컨텍스트에 들어갈 문서를 고르는 역할을 맡았다.
이렇게 나누고 나니 검색 흐름을 더 이해하기 쉬웠다. 벡터 검색은 후보 탐색, reranking은 근거 품질을 높이기 위한 보정 단계에 가까웠다. 환각을 없애는 것은 아니지만, 약한 컨텍스트를 LLM에 넘겨서 생기는 문제를 줄이는 데 도움이 됐다.
적용 내용
RAG를 적용할 때는 모델의 표현을 통제하는 것만 보지 않았다. 답변 이전 단계에서 검색 범위를 먼저 좁히고, 검색 결과의 품질을 높이는 쪽도 같이 봤다.
문서 조각이 너무 넓으면 관련 없는 내용이 함께 들어가고, 너무 좁으면 필요한 문맥이 빠질 수 있다. 그래서 검색 결과를 어떻게 자르고, 어떤 순서로 컨텍스트에 넣을지 계속 확인해야 했다.
당시 사용한 구성은 아래와 같았다.
- Vector DB: Pinecone
- Embedding: Upstage Embeddings
- Reranking: 질문 관련도 기준 후보 문서 재정렬
- LLM: Upstage Solar Pro 2
- Framework: LangChain
- Backend: Node.js, Express
기술을 적용하는 것만큼 답변의 범위를 정하는 일도 필요했다. 모델이 문서를 기반으로 설명하게 만들되, 문서 밖의 내용을 단정하지 않도록 설계를 맞췄다.
SSE 스트리밍 적용 이유
RAG를 적용하면 검색을 하고, reranking을 거치고, 검색 결과를 프롬프트에 넣고, 다시 답변을 생성해야 한다. 그래서 단순 LLM 호출보다 응답 시간이 길어질 수 있었다.
사용자 입장에서는 로딩만 오래 보이면 서비스가 멈춘 것처럼 느낄 수 있다. 그래서 응답을 한 번에 보내지 않고 Server-Sent Events(SSE)로 생성되는 내용을 조금씩 보내는 방식을 적용했다.
이 방식으로 얻고 싶었던 것은 두 가지였다.
- 생성 과정이 화면에 보이게 해서 대기감을 줄인다.
- 전체 답변이 끝나기 전에도 사용자가 진행 중임을 확인할 수 있게 한다.
LLM 기능에서는 품질뿐 아니라 사용자 체감도 같이 봐야 했다. 특히 RAG처럼 검색과 생성이 함께 들어가는 구조에서는 응답 흐름을 어떻게 보여줄지도 함께 고려해야 했다.
정리
이 경험을 통해 LLM 관련 문제는 모델만 교체하기보다 주변 파이프라인을 함께 설계해야 하는 경우가 많다는 점을 확인했다.
특히 문서 기반 답변에서는 아래 내용을 확인했다.
- 답변이 어떤 문서를 근거로 하는가
- 검색 결과가 질문 의도와 충분히 맞는가
- 모델이 컨텍스트 밖 내용을 단정하지 않는가
- 사용자가 답변의 근거를 확인할 수 있는가
- 생성 시간이 길어질 때 사용자에게 진행 상태를 보여주는가
RAG는 환각을 완전히 없애는 도구라기보다, 답변의 근거를 시스템 안에 넣기 위한 구조였다. DocDoc에서는 문서 파싱, 임베딩, 검색, reranking, 프롬프트 구성, SSE 스트리밍이 모두 맞물려야 답변을 조금 더 검증 가능한 형태로 만들 수 있다는 점을 확인했다.