Code Place를 운영하던 중 PostgreSQL 인스턴스가 정상적으로 실행되지 않는 상황을 겪었다. 처음에는 DB 자체 문제처럼 보였다. CNPG 상태에는 인스턴스가 활성화되지 않았다는 메시지가 보였고, system ID를 보고하지 못했다는 메시지도 함께 나왔다.
하지만 Kubernetes 이벤트와 Longhorn 상태를 함께 확인하니 단순히 PostgreSQL만의 문제로 보기 어려웠다. 시작점은 WAL 증가로 인한 디스크 압박에 가까웠고, 그 결과가 CNPG 상태 이상과 Longhorn 볼륨 문제로 함께 드러나고 있었다.
처음에는 PostgreSQL Pod를 다시 띄우거나 오퍼레이터를 건드리면 될 것 같았다. 다만 원인을 확인하기 전에 재시작부터 하면 증상만 바뀔 수 있어서, DB, Kubernetes, Longhorn, 노드 상태를 나눠서 확인했다.
이 글은 WAL 증가 이후 Longhorn과 CNPG가 얽힌 장애를 어떤 순서로 복구했는지 정리한 기록이다.
처음 보인 문제
가장 먼저 눈에 띈 것은 CNPG 상태 메시지였다.
Detected low-disk space condition, avoid starting the instanceWaiting for the instances to become activeInstances are present, but none have reported a system ID- 상황에 따라
Dangling PVC처럼 보이는 상태
처음 보면 PostgreSQL 인스턴스 자체가 잘못된 상태라고 생각하기 쉬운 메시지였다. 나도 처음에는 PostgreSQL 내부 문제를 먼저 떠올렸다.
하지만 여기서 바로 Pod를 재시작하거나 오퍼레이터를 다시 올리지는 않았다. 원인 확인 없이 증상만 바꿀 가능성이 있었기 때문이다.
특히 이번 장애는 WAL 증가로 서버 용량이 부족해진 뒤 시작됐다. 그래서 단순히 "DB가 왜 안 뜨지?"가 아니라 "DB가 정상적으로 뜨기 위한 스토리지 조건이 아직 맞는가?"부터 다시 봐야 했다.
운영 환경
환경은 k3s 기반 멀티 노드 클러스터였고, PostgreSQL은 CloudNativePG(CNPG)로 운영하고 있었다. 영속 스토리지는 Longhorn을 사용했다.
이 조합은 평소에는 각자 역할이 나뉘어 있지만, 한 번 문제가 생기면 확인할 곳이 많아진다. DB가 안 뜬다고 해서 DB만 확인하면 끝나는 구조가 아니었다. Kubernetes, CNPG, PVC, Longhorn 볼륨, 실제 노드의 장치 상태까지 함께 확인해야 했다.
특히 Longhorn replica 구성을 유지하려면 각 노드에 충분한 물리 디스크 여유 공간이 필요했다. PVC나 Longhorn 볼륨을 확장해도, 실제 노드 쪽 용량이 따라오지 않으면 replica를 정상적으로 다시 붙이기 어려웠다.
처음 세운 가설
처음에는 대략 네 가지 가능성을 두고 확인했다.
- PostgreSQL 인스턴스 자체 상태가 깨져서 정상 기동이 안 되는 경우
- WAL 증가와 디스크 부족으로 CNPG가 인스턴스 기동을 막고 있는 경우
- CNPG가 PVC나 볼륨 상태를 정상으로 보지 못해 인스턴스를 실행하지 못하는 경우
- 실제 원인은 Longhorn 쪽인데, 그 결과가 CNPG 상태 이상으로 드러나는 경우
어떤 가설이 맞는지 바로 정하기보다는, 실제로 어느 단계에서 막히는지부터 확인했다.
원인을 확인한 과정
이 문제에서 가장 먼저 한 일은 장애를 단순히 "DB 문제"로 묶지 않는 것이었다. 대신 아래처럼 나눠 확인했다.
- CNPG: 클러스터 상태 메시지, primary/replica 인식, 인스턴스 활성화 여부
- Kubernetes: Pod 이벤트, PVC 상태, volume attachment, mount 실패 여부
- Longhorn: replica 상태, 볼륨 확장, share-manager 상태, 디스크 스케줄링 가능 여부
- 노드/리눅스: 실제 마운트 충돌, 장치 사용 상태,
multipathd같은 시스템 프로세스 간섭 여부 - PostgreSQL: replication slot, WAL 유지 상태, 복제 관련 정리 필요 여부
이렇게 나눠 확인하니, CNPG 메시지는 원인이라기보다 결과일 수도 있다고 볼 수 있었다.
CNPG 메시지 확인
예를 들어 system ID를 보고하지 못했다는 것은 PostgreSQL 인스턴스가 정상 기동까지 가지 못했다는 뜻이다. 하지만 그 이유가 꼭 PostgreSQL 내부 손상이라고 단정되지는 않는다.
데이터를 올려야 할 스토리지가 정상적으로 연결되지 않아 기동이 끝까지 가지 못했을 수도 있었다. 그래서 이 상태를 보고는 "DB가 왜 깨졌지"보다 "DB가 왜 여기서 멈췄지"라는 쪽으로 확인했다.
low-disk condition도 마찬가지였다. 실제 디스크가 부족한지, PVC 확장 상태에 문제가 있는지, Longhorn에서 볼륨을 정상적으로 사용할 수 없는지까지 함께 확인해야 했다.
오퍼레이터의 메시지는 단서가 됐다. 다만 그 메시지를 바로 원인으로 보지는 않았다.
스토리지 쪽에서 나온 단서
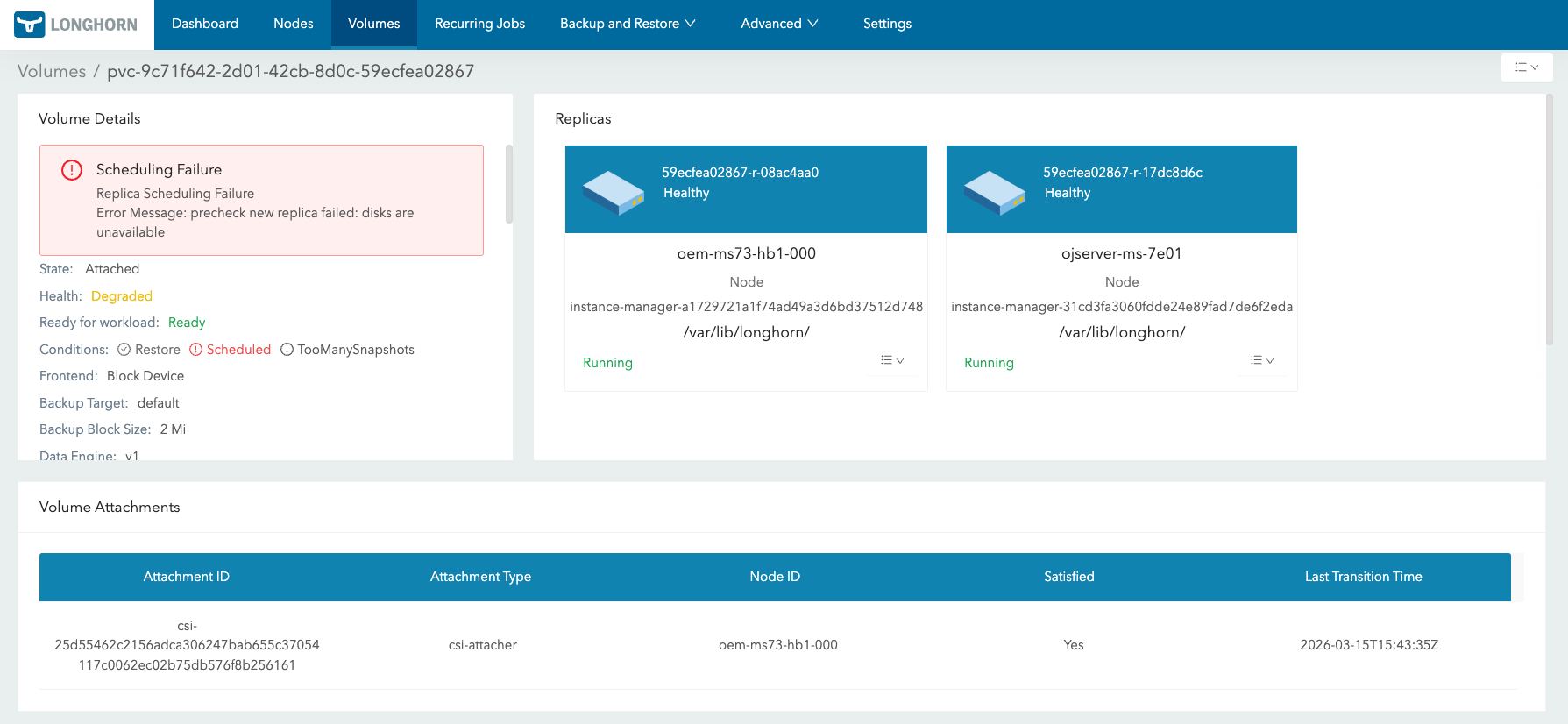
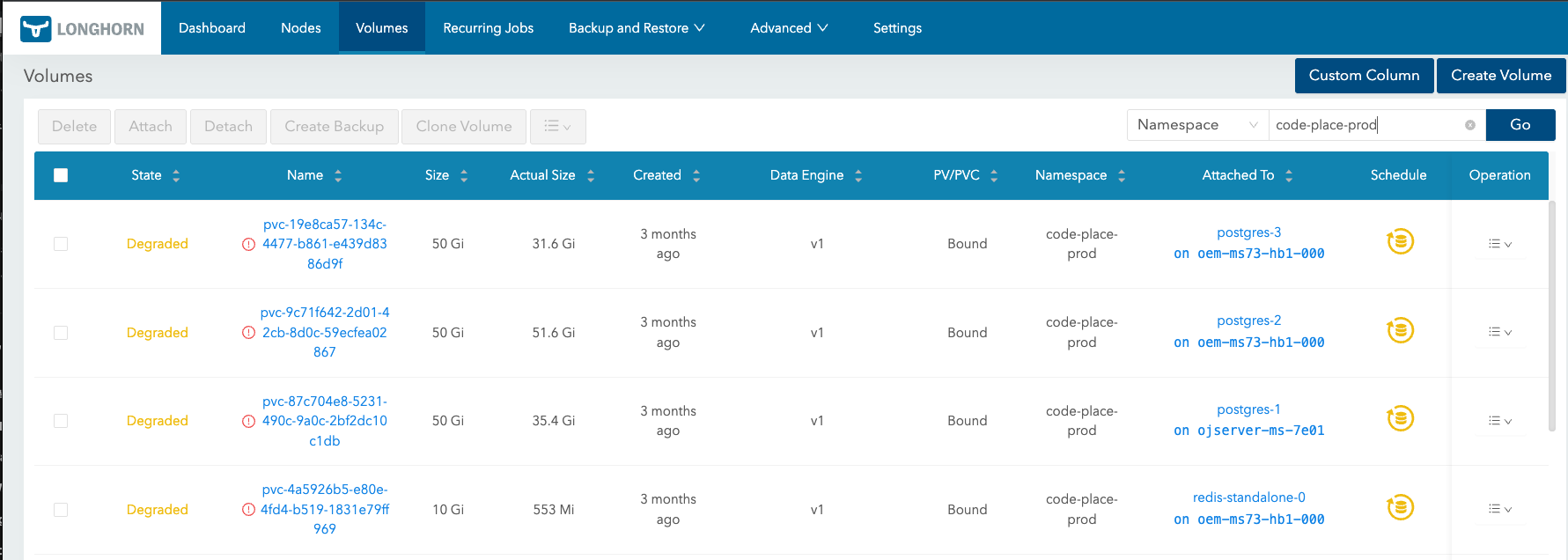
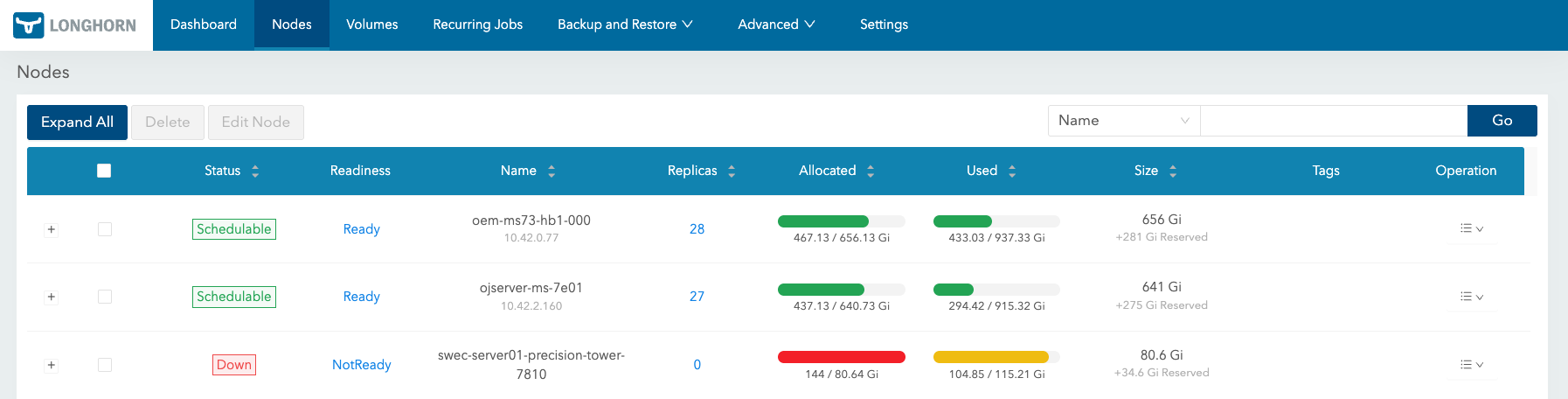
스토리지 쪽을 확인하기 시작하자 CNPG보다 아래를 더 의심할 만한 단서가 늘어났다.
- WAL 증가로 서버 디스크 여유 공간이 빠르게 줄어들었다.
- 긴급하게 용량을 확보하려고 했지만, 3번 노드의 여유 공간이 부족했다.
- Longhorn replica 3개 구성을 그대로 유지하기 어려워졌다.
- PVC 자체는 복구했지만, CNPG가 곧바로 기대한 인스턴스를 살리지는 않았다.
- 이후 mount error가 발생했고, 노드의 장치 관리 상태까지 확인해야 했다.
여기서 헷갈렸던 부분은 "리소스가 있다"와 "실제로 그 리소스를 쓸 수 있다"가 다르다는 점이었다.
PVC가 Bound라고 해서 실제 워크로드가 그 볼륨을 문제없이 mount해 쓰고 있다는 뜻은 아니었다. 볼륨 확장이 끝났다고 해서 attach나 mount까지 다 끝난 것도 아니었다. 또 PVC가 존재한다고 해서 CNPG가 그 PVC를 곧바로 정상 인스턴스 후보로 다시 채택하는 것도 아니었다.
이 시점부터는 CNPG가 기동하지 않는 이유를 DB 내부보다 스토리지와 오퍼레이터 reconciliation 흐름에서 더 집중적으로 찾았다.
실제 복구 타임라인


이번 장애의 시작점은 WAL 증가로 인한 서버 용량 부족이었다. WAL이 계속 쌓이면서 디스크 여유 공간이 줄어들었고, 결국 PostgreSQL 인스턴스가 정상적으로 유지되지 못하는 상황까지 이어졌다.
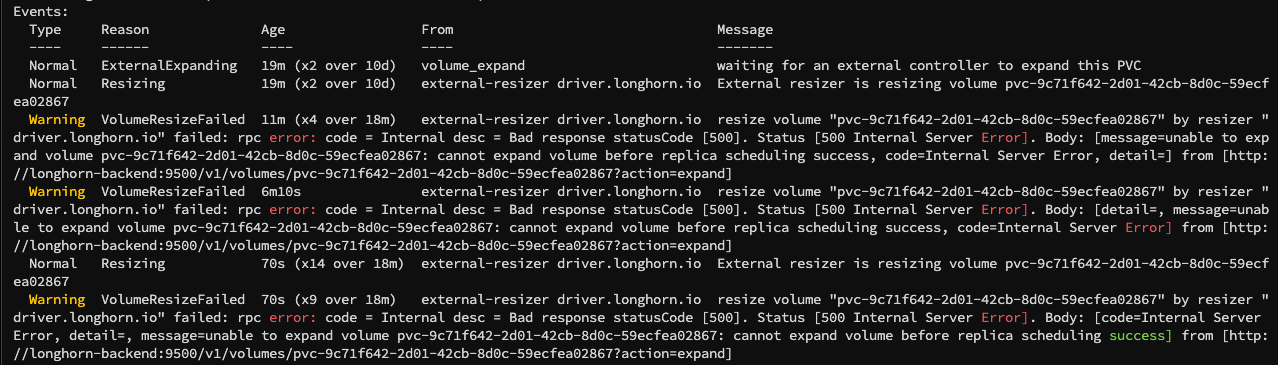
처음에는 긴급하게 용량을 확보하려고 했다. 하지만 당시 3번 노드의 여유 공간이 부족해 Longhorn replica 3개 구성을 그대로 유지하기 어려웠다. 그래서 우선 Longhorn에서 3번 노드를 배제하고 replica 수를 2개로 줄였다. 모든 replica를 바로 맞추기보다는, 먼저 다시 띄울 수 있는 구성을 만드는 쪽을 선택했다.
이후 추가 용량을 확보했고 PVC 자체는 다시 복구할 수 있었다. 하지만 PVC가 복구됐다고 해서 CNPG가 곧바로 인스턴스를 정상적으로 살리지는 않았다. 특히 2번 인스턴스를 기준으로 복구되기를 기대했지만, CNPG는 한 번 dangling PVC처럼 본 대상을 바로 정상 인스턴스 후보로 보지 않는 것처럼 동작했다.
CNPG 관련 Pod를 재시작해도 원하는 방향으로 reconciliation이 진행되지 않았다. 그래서 남아 있던 1번, 3번 Pod를 정리했고, 그 뒤에야 CNPG가 2번 인스턴스를 기준으로 다시 살리기 시작했다.
하지만 여기서 다시 mount error가 발생했다. 이 문제는 단순히 PostgreSQL이나 CNPG 상태만 봐서는 해결하기 어려웠고, 실제 노드의 장치와 mount 상태까지 확인해야 했다. 확인 과정에서 multipathd가 Longhorn이 사용해야 할 블록 장치에 간섭할 가능성을 봤고, 노드에서 multipathd를 중지하고 비활성화한 뒤 다시 mount를 시도했다. 이후 mount 문제가 풀렸고, 2번 인스턴스를 기준으로 복구를 이어갈 수 있었다.
중간에 노드 상태를 정리하기 위한 재부팅도 있었지만, mount error가 풀린 쪽에 더 가까운 조치는 단순 재부팅보다 multipathd 간섭 가능성을 제거한 것이었다. 그래서 이 부분은 "다시 켜니 됐다"로만 정리하지 않았다.
2번이 살아난 뒤에는 나머지 1번과 3번 인스턴스도 순서대로 복구를 시도했다. 1번은 정상적으로 복구됐지만, 3번은 앞서 긴급 대응 과정에서 Longhorn 볼륨 크기를 늘린 영향으로 다시 붙이기 어려웠다. replica 3개 구성을 유지하려면 확장된 볼륨 크기만큼 각 노드에도 충분한 물리 용량이 필요했기 때문이다.
3번 노드의 기존 용량만으로는 부족했기 때문에, 해당 노드에 있던 빈 디스크를 새로 마운트하고 Longhorn 디스크로 추가했다. 이후 3번 인스턴스도 다시 복구할 수 있었다.
마지막으로 데이터베이스 replication slot과 WAL 상태를 확인했다. 장애 이후 불필요한 replication slot 때문에 WAL이 계속 유지되는 상황이 있으면 다시 디스크를 압박할 수 있기 때문이다. 그래서 복구가 끝난 뒤에도 replication slot과 WAL 정리 상태까지 확인했다.
CNPG RW/RO 엔드포인트 확인
복구 이후에는 애플리케이션이 실제로 어떤 PostgreSQL 서비스에 연결되는지도 다시 확인했다. 연결 자체가 된다고 해서 쓰기 가능한 primary에 붙었다는 뜻은 아니기 때문이다.
CloudNativePG는 보통 역할별 서비스를 따로 만든다.
postgres-rw: primary를 대상으로 하는 read-write 엔드포인트postgres-ro: replica를 대상으로 하는 read-only 엔드포인트postgres-r: 읽기 계열 접근에 사용하는 엔드포인트
이 구분을 놓치면 SELECT는 정상인데 INSERT만 실패하는 상황을 DB 장애나 애플리케이션 트랜잭션 설정 문제로 오해할 수 있다. 특히 cannot execute INSERT in a read-only transaction 같은 메시지를 보면 @Transactional(readOnly = true)부터 의심하기 쉽지만, 실제로는 read-only replica에 연결된 결과일 수 있다.
현재 세션이 standby에 붙었는지는 PostgreSQL 안에서도 확인할 수 있다.
SELECT pg_is_in_recovery();
값이 true라면 현재 연결 대상은 standby다. 그래서 복구 후에는 연결 성공 여부만 보지 않고, 읽기와 쓰기가 모두 되는지, 애플리케이션이 의도한 -rw 서비스로 연결되는지도 확인했다.
원인을 좁혀간 순서
실제로는 아래 순서로 생각이 바뀌었다.
1. PostgreSQL 상태
처음부터 PostgreSQL 내부 상태만 의심하지 않았다. 오퍼레이터 상태 메시지와 스토리지 상태를 함께 확인했다. DB가 실행되지 않는 것은 맞지만, 시작점은 WAL 증가와 디스크 압박에 가까웠다.
2. replica 수 조정
3번 노드의 여유 공간이 부족한 상태에서 replica 3개 구성을 바로 맞추기는 어려웠다. 그래서 우선 Longhorn에서 3번 노드를 배제하고 replica 수를 2개로 줄여, 살아날 수 있는 인스턴스부터 복구하는 방향을 선택했다.
3. PVC 재채택
PVC를 복구했다고 해서 CNPG가 바로 해당 PVC를 정상 인스턴스로 다시 살리는 것은 아니었다. 한 번 dangling PVC처럼 판단된 뒤에는 단순 재시작만으로 원하는 방향으로 reconciliation이 진행되지 않았다.
4. Pod 정리
남아 있던 1번, 3번 Pod가 있는 상태에서는 CNPG가 기대한 방식으로 2번을 살리지 않았다. 그래서 나머지 Pod를 정리했고, 그 뒤에야 2번 인스턴스를 기준으로 복구가 시작됐다.
5. 노드 장치 상태 확인
2번 인스턴스를 살리는 과정에서 mount error가 다시 발생했다. 이때는 CNPG나 PostgreSQL만 볼 문제가 아니었고, 실제 노드의 장치와 mount 상태까지 확인해야 했다.
특히 multipathd가 Longhorn이 관리해야 할 블록 장치를 건드리거나, Longhorn이 기대하는 방식과 다르게 장치를 인식하게 만들 가능성을 봤다. 그래서 multipathd를 중지하고 비활성화한 뒤 mount를 다시 시도했고, 이후 2번 인스턴스를 복구할 수 있었다.
이 문제는 별도로 정리할 만한 내용이었다. Longhorn에서 볼륨이 보인다고 해서 실제 노드에서 mount 가능한 상태라는 뜻은 아니었고, share-manager 상태, ext4 메시지, already mounted or mount point busy, multipathd 같은 단서를 함께 봐야 했다. 이 부분은 별도 글인 Longhorn mount conflict 정리에서 더 자세히 다뤘다.
6. 물리 디스크 추가
1번은 복구됐지만, 3번은 Longhorn 볼륨 확장 이후 필요한 물리 용량을 충족하지 못했다. 그래서 3번 노드에 빈 디스크를 새로 마운트하고 Longhorn 디스크로 추가했다. 이후 3번 인스턴스까지 복구하면서 다시 replica 3개 구성을 맞출 수 있었다.
7. replication slot과 WAL
장애의 시작이 WAL 증가였기 때문에, 복구 이후에도 replication slot과 WAL 상태를 확인했다. 불필요한 slot이 남아 WAL이 계속 유지되면 같은 문제가 다시 발생할 수 있기 때문이다.
8. 애플리케이션 CNPG 엔드포인트 확인
마지막에는 애플리케이션이 read-only replica가 아니라 쓰기 가능한 primary 엔드포인트를 바라보는지 확인했다. 연결 성공만으로는 충분하지 않았고, SELECT와 INSERT가 모두 의도한 경로에서 동작하는지 봐야 했다.
이후 확인 순서
이번 일을 겪고 나서, 오퍼레이터가 보여주는 상태와 실제 원인을 조금 나눠서 보게 됐다.
CloudNativePG도 Longhorn도 많은 것을 자동화해준다. 하지만 복구 과정에서는 "리소스가 존재한다"와 "오퍼레이터가 그 리소스를 정상 후보로 다시 채택한다"를 나눠서 봐야 했다.
비슷한 상황이면 아래 순서로 확인하려고 한다.
- CNPG 상태 메시지를 본다.
- WAL 증가나 low disk condition이 있는지 확인한다.
- Kubernetes 이벤트와 PVC 상태를 함께 확인한다.
- Longhorn의 replica, share-manager, volume scheduling 상태를 확인한다.
- 필요하면 노드에서 실제 장치와 mount 상태까지 내려간다.
multipathd처럼 Longhorn 장치 관리와 충돌할 수 있는 시스템 프로세스를 확인한다.- 복구 이후 replication slot과 WAL 정리 상태를 확인한다.
- CNPG의 RW/RO 서비스 엔드포인트가 애플리케이션 설정과 맞는지 확인한다.
- 그 다음에 PostgreSQL 내부 복구가 필요한지 본다.
마무리
이번 일 이후로 DB 인스턴스가 비정상처럼 보이면 DB만 보지 않고, 스토리지나 노드 상태도 같이 확인하게 됐다.
이번에는 WAL 증가, Longhorn replica, CNPG reconciliation, PVC 상태, mount error, multipathd, replication slot이 각각 따로 보였지만, 실제로는 하나의 복구 흐름 안에서 이어져 있었다.
정리하면, 단순히 Pod를 다시 띄우는 것보다 오퍼레이터가 다시 정상 상태로 볼 수 있는 조건을 맞추는 과정이 필요했다.